The Electoral College, established by Article II, Section 1 of the U.S. Constitution, serves as the mechanism for electing the President of the United States. Each state is granted a number of electors equal to its representation in Congress—comprising both Senators and Representatives. Over time, the states have developed their own methods for allocating these electoral votes (ECVs), often opting for a “winner-takes-all” system based on the state’s popular vote. Notably, Maine and Nebraska allocate their ECVs differently, by congressional district.
In this mini-project, we examine the impact of alternative electoral allocation methods on U.S. presidential election outcomes, specifically investigating whether different methods could affect perceived biases in the Electoral College system. Our analysis will simulate alternative ECV allocations using historical voting data, assessing how proportional or district-based allocations might alter electoral outcomes.
Data Set-Up and Initial Exploration
To prepare the data, I wrote R code that automates the download of U.S. congressional shapefiles1 from 1976 to 2022, organized into two main tasks. For 1976-2012, the code downloads files from the UCLA Political Science website, using a systematic naming convention to save each file in a designated “shapefiles” directory. For 2014-2022, it pulls files from the U.S. Census Bureau2 and saves them in a separate “census_shapefiles” directory. The code checks for existing files locally to prevent redundant downloads, optimizing server load and storage efficiency. Additionally, I manually downloaded U.S. House election vote data3 and statewide presidential vote4 counts from 1976 to 2022 from the MIT Election Data Science Lab to incorporate into the project.
Show the code
# Load necessary packagesif(!require("sf")) install.packages("sf")library(sf)if(!require("tigris")) install.packages("tigris")library(tigris)if(!require("gganimate")) install.packages("gganimate")library(gganimate)if(!require("usmap")) install.packages("usmap")library(usmap)library(httr)library(tidyverse)library(dplyr)library(ggplot2)library(gt)library(sf)library(stringr)# Define file pathspresident_data_path <-"C:\\Users\\w3038\\Downloads\\STA 9750\\1976-2020-president.csv"house_data_path <-"C:\\Users\\w3038\\Downloads\\STA 9750\\1976-2022-house.csv"# Load the datasetspresident_data <-read.csv(president_data_path)house_data <-read.csv(house_data_path)# Display a preview of the president data in a gt tablepresident_data %>%slice_head(n =10) %>%# Display the first 10 rowsgt() %>%tab_header(title ="President Data (1976-2020)" ) %>%cols_label(# Customize column labels here if needed, for example:year ="Year",state ="State",candidatevotes ="Candidate Votes"# Add other columns as desired ) %>%fmt_number(columns =where(is.numeric),decimals =0 )
President Data (1976-2020)
Year
State
state_po
state_fips
state_cen
state_ic
office
candidate
party_detailed
writein
Candidate Votes
totalvotes
version
notes
party_simplified
1,976
ALABAMA
AL
1
63
41
US PRESIDENT
CARTER, JIMMY
DEMOCRAT
FALSE
659,170
1,182,850
20,210,113
NA
DEMOCRAT
1,976
ALABAMA
AL
1
63
41
US PRESIDENT
FORD, GERALD
REPUBLICAN
FALSE
504,070
1,182,850
20,210,113
NA
REPUBLICAN
1,976
ALABAMA
AL
1
63
41
US PRESIDENT
MADDOX, LESTER
AMERICAN INDEPENDENT PARTY
FALSE
9,198
1,182,850
20,210,113
NA
OTHER
1,976
ALABAMA
AL
1
63
41
US PRESIDENT
BUBAR, BENJAMIN ""BEN""
PROHIBITION
FALSE
6,669
1,182,850
20,210,113
NA
OTHER
1,976
ALABAMA
AL
1
63
41
US PRESIDENT
HALL, GUS
COMMUNIST PARTY USE
FALSE
1,954
1,182,850
20,210,113
NA
OTHER
1,976
ALABAMA
AL
1
63
41
US PRESIDENT
MACBRIDE, ROGER
LIBERTARIAN
FALSE
1,481
1,182,850
20,210,113
NA
LIBERTARIAN
1,976
ALABAMA
AL
1
63
41
US PRESIDENT
TRUE
308
1,182,850
20,210,113
NA
OTHER
1,976
ALASKA
AK
2
94
81
US PRESIDENT
FORD, GERALD
REPUBLICAN
FALSE
71,555
123,574
20,210,113
NA
REPUBLICAN
1,976
ALASKA
AK
2
94
81
US PRESIDENT
CARTER, JIMMY
DEMOCRAT
FALSE
44,058
123,574
20,210,113
NA
DEMOCRAT
1,976
ALASKA
AK
2
94
81
US PRESIDENT
MACBRIDE, ROGER
LIBERTARIAN
FALSE
6,785
123,574
20,210,113
NA
LIBERTARIAN
Show the code
# Display a preview of the house data in a gt tablehouse_data %>%slice_head(n =10) %>%# Display the first 10 rowsgt() %>%tab_header(title ="House Data (1976-2022)" ) %>%cols_label(# Customize column labels here if needed, for example:year ="Year",state ="State",candidatevotes ="Candidate Votes"# Add other columns as desired ) %>%fmt_number(columns =where(is.numeric),decimals =0 )
House Data (1976-2022)
Year
State
state_po
state_fips
state_cen
state_ic
office
district
stage
runoff
special
candidate
party
writein
mode
Candidate Votes
totalvotes
unofficial
version
fusion_ticket
1,976
ALABAMA
AL
1
63
41
US HOUSE
1
GEN
FALSE
FALSE
BILL DAVENPORT
DEMOCRAT
FALSE
TOTAL
58,906
157,170
FALSE
20,230,706
FALSE
1,976
ALABAMA
AL
1
63
41
US HOUSE
1
GEN
FALSE
FALSE
JACK EDWARDS
REPUBLICAN
FALSE
TOTAL
98,257
157,170
FALSE
20,230,706
FALSE
1,976
ALABAMA
AL
1
63
41
US HOUSE
1
GEN
FALSE
FALSE
WRITEIN
TRUE
TOTAL
7
157,170
FALSE
20,230,706
FALSE
1,976
ALABAMA
AL
1
63
41
US HOUSE
2
GEN
FALSE
FALSE
J CAROLE KEAHEY
DEMOCRAT
FALSE
TOTAL
66,288
156,362
FALSE
20,230,706
FALSE
1,976
ALABAMA
AL
1
63
41
US HOUSE
2
GEN
FALSE
FALSE
WILLIAM L "BILL" DICKINSON
REPUBLICAN
FALSE
TOTAL
90,069
156,362
FALSE
20,230,706
FALSE
1,976
ALABAMA
AL
1
63
41
US HOUSE
2
GEN
FALSE
FALSE
WRITEIN
TRUE
TOTAL
5
156,362
FALSE
20,230,706
FALSE
1,976
ALABAMA
AL
1
63
41
US HOUSE
3
GEN
FALSE
FALSE
BILL NICHOLS
DEMOCRAT
FALSE
TOTAL
106,935
108,048
FALSE
20,230,706
FALSE
1,976
ALABAMA
AL
1
63
41
US HOUSE
3
GEN
FALSE
FALSE
OGBURN GARDNER
PROHIBITION
FALSE
TOTAL
1,111
108,048
FALSE
20,230,706
FALSE
1,976
ALABAMA
AL
1
63
41
US HOUSE
3
GEN
FALSE
FALSE
WRITEIN
TRUE
TOTAL
2
108,048
FALSE
20,230,706
FALSE
1,976
ALABAMA
AL
1
63
41
US HOUSE
4
GEN
FALSE
FALSE
LEONARD WILSON
REPUBLICAN
FALSE
TOTAL
34,531
176,022
FALSE
20,230,706
FALSE
Show the code
#UCLA Shapefile# Create directory for shapefiles with recursive creationdir.create("data/shapefiles", showWarnings =FALSE, recursive =TRUE)# Function to download shapefiles systematicallydownload_shapefiles <-function(start, end, base_url) {for (session in start:end) { file_name <-paste0("districts", sprintf("%03d", session), ".zip") url <-paste0(base_url, file_name) destfile <-file.path("data/shapefiles", file_name)if (!file.exists(destfile)) {GET(url, write_disk(destfile, overwrite =TRUE))message(paste("Downloaded:", file_name)) } else {message(paste("File already exists:", file_name)) } }}# Define the base URL and download the filesbase_url <-"https://cdmaps.polisci.ucla.edu/shp/"download_shapefiles(93, 112, base_url)#Census# Create directory for shapefiles if it doesn't existdir.create("data/census_shapefiles", showWarnings =FALSE, recursive =TRUE)# List of download URLs and file names for the shapefilesshapefile_urls <-c("https://www2.census.gov/geo/tiger/TIGER2014/CD/tl_2014_us_cd114.zip","https://www2.census.gov/geo/tiger/TIGER2015/CD/tl_2015_us_cd114.zip","https://www2.census.gov/geo/tiger/TIGER2016/CD/tl_2016_us_cd115.zip","https://www2.census.gov/geo/tiger/TIGER2017/CD/tl_2017_us_cd115.zip","https://www2.census.gov/geo/tiger/TIGER2018/CD/tl_2018_us_cd116.zip","https://www2.census.gov/geo/tiger/TIGER2019/CD/tl_2019_us_cd116.zip","https://www2.census.gov/geo/tiger/TIGER2020/CD/tl_2020_us_cd116.zip","https://www2.census.gov/geo/tiger/TIGER2021/CD/tl_2021_us_cd116.zip","https://www2.census.gov/geo/tiger/TIGER2022/CD/tl_2022_us_cd116.zip")# Function to download shapefiles systematicallydownload_shapefiles_census <-function(urls, dest_dir) {for (url in urls) { file_name <-basename(url) destfile <-file.path(dest_dir, file_name)# Download file only if it doesn't already existif (!file.exists(destfile)) {GET(url, write_disk(destfile, overwrite =TRUE))message(paste("Downloaded:", file_name)) } else {message(paste("File already exists:", file_name)) } }}# Call the download functiondownload_shapefiles_census(shapefile_urls, "data/census_shapefiles")
Initial Exploration of Vote Count Data
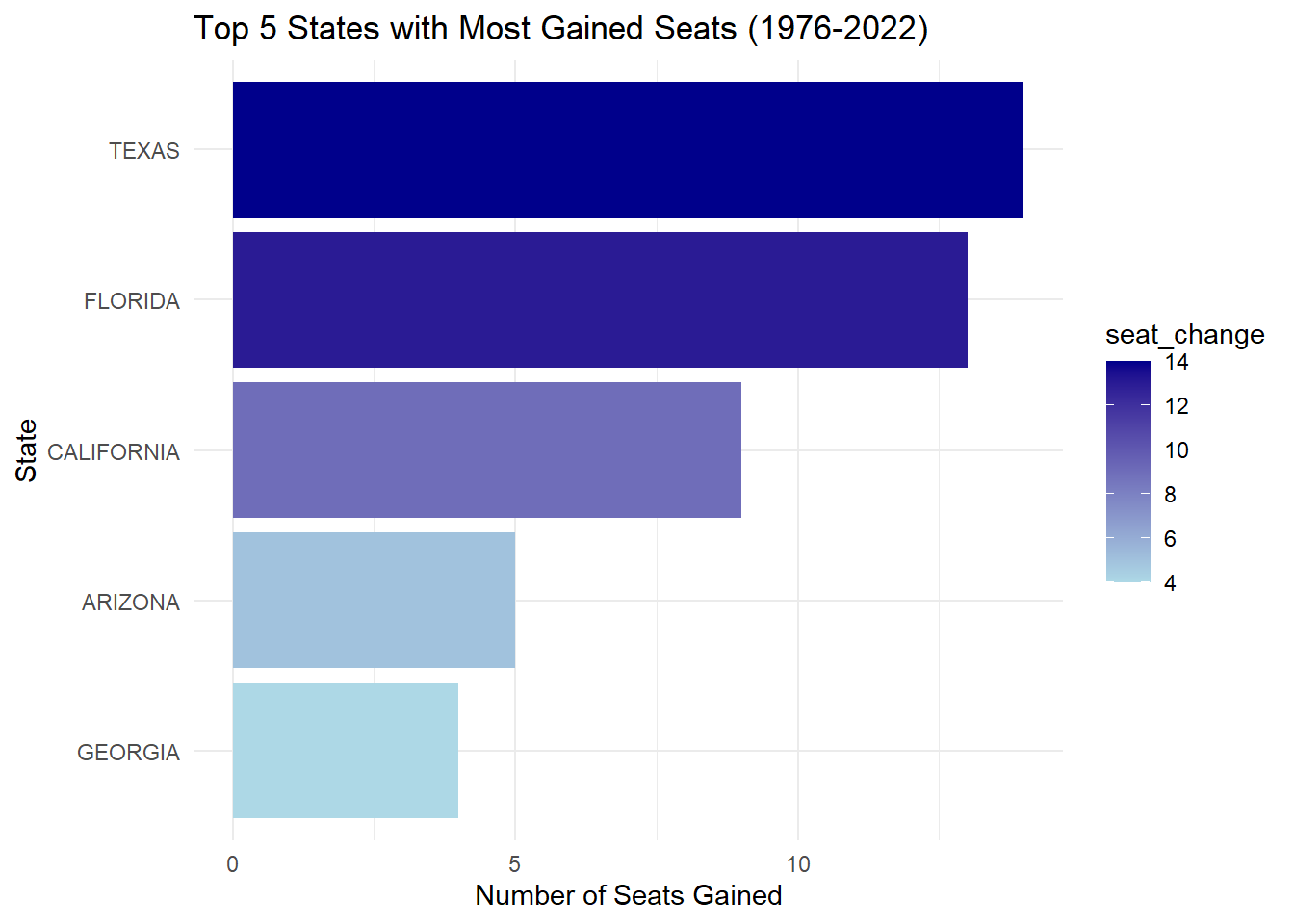
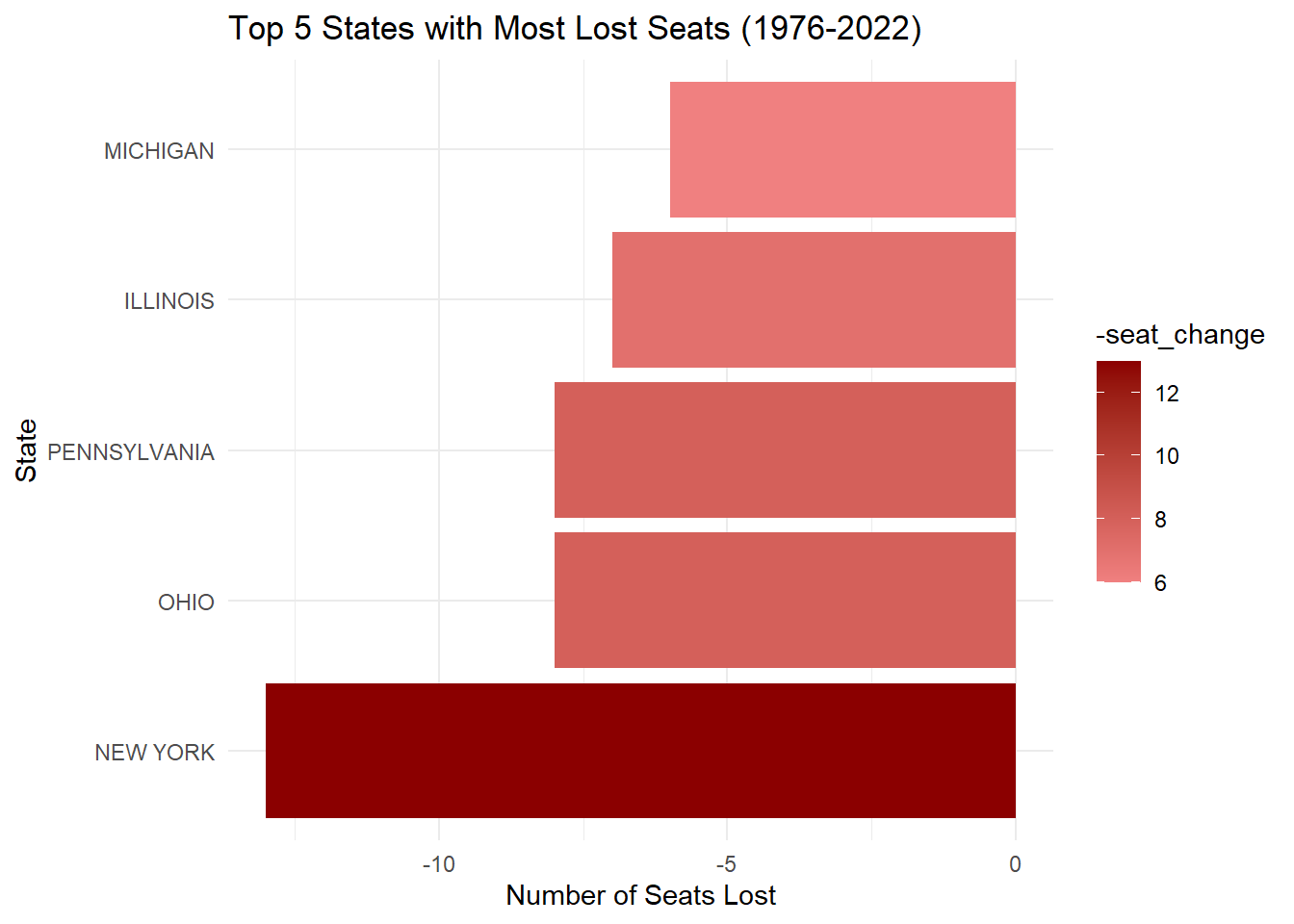
To analyze which states gained or lost the most seats in the U.S. House of Representatives between 1976 and 2022, I first filtered the House data to include only those years. Then, I grouped the data by year and state to calculate the number of seats per state. After determining the seat changes, I identified the top 5 states with the most significant gains and lost as follows:
Show the code
#3.1 Which states have gained and lost the most seats in the US House of Representatives between 1976 and 2022?# Filter data for relevant years (1976 and 2022)house_seats <- house_data %>%filter(year %in%c(1976, 2022)) %>%distinct(year, state, district) %>%group_by(year, state) %>%summarise(seat_count =n(), .groups ="drop")# Calculate seat changesseat_changes <- house_seats %>%pivot_wider(names_from = year, values_from = seat_count, names_prefix ="year_") %>%mutate(seat_change = year_2022 - year_1976) %>%arrange(desc(seat_change))# Separate states with the highest seat changestop_gained <- seat_changes %>%top_n(5, seat_change)top_lost <- seat_changes %>%top_n(-5, seat_change)# Plot for top gained seatsgained_plot <-ggplot(top_gained, aes(x =reorder(state, seat_change), y = seat_change, fill = seat_change)) +geom_bar(stat ="identity") +coord_flip() +labs(title ="Top 5 States with Most Gained Seats (1976-2022)",x ="State",y ="Number of Seats Gained") +scale_fill_gradient(low ="lightblue", high ="darkblue") +theme_minimal()# Plot for top lost seatslost_plot <-ggplot(top_lost, aes(x =reorder(state, seat_change), y = seat_change, fill =-seat_change)) +geom_bar(stat ="identity") +coord_flip() +labs(title ="Top 5 States with Most Lost Seats (1976-2022)",x ="State",y ="Number of Seats Lost") +scale_fill_gradient(low ="lightcoral", high ="darkred") +theme_minimal()# Display plotslist(gained_plot, lost_plot)
[[1]]
[[2]]
In New York State, the “fusion” voting system allows a candidate to appear on multiple party lines, with their votes across all lines being totaled. This system can sometimes affect the outcome of elections. The goal of this analysis is to determine if the outcome of any U.S. House elections in New York would have changed if the fusion system had not been used, meaning candidates would only receive votes from their major party lines (Democrat or Republican).
This code analyzes U.S. House elections in New York State to identify instances where the fusion voting system might have changed the election outcome. It filters the data for New York House races, focusing on candidates from the Democrat and Republican parties. The code calculates total votes across all lines (fusion) and major party votes only (non-fusion) for each candidate. It then determines the winner in both scenarios and compares them to highlight elections where the fusion system resulted in a different winner. The results are displayed in a formatted table using the gt package.
Show the code
library(gt)library(dplyr)#3.2# Filter for New York State and U.S. House electionsny_house_data <- house_data %>%filter(state =="NEW YORK", office =="US HOUSE")# Filter for candidates from major parties only (Democrat or Republican)# and keep records for candidates with votes across different linesfusion_analysis <- ny_house_data %>%mutate(is_major_party = party %in%c("DEMOCRAT", "REPUBLICAN")) %>%group_by(year, district, candidate) %>%summarise(total_votes_all_lines =sum(candidatevotes),major_party_votes =sum(candidatevotes[is_major_party]),.groups ="drop" )# Determine the election winner by both fusion and non-fusion scenarios# Winner with fusion system (total across all lines)winners_fusion <- fusion_analysis %>%group_by(year, district) %>%filter(total_votes_all_lines ==max(total_votes_all_lines)) %>%select(year, district, candidate, total_votes_all_lines) %>%rename(fusion_winner = candidate, fusion_votes = total_votes_all_lines)# Winner without fusion system (major party line votes only)winners_nonfusion <- fusion_analysis %>%group_by(year, district) %>%filter(major_party_votes ==max(major_party_votes)) %>%select(year, district, candidate, major_party_votes) %>%rename(nonfusion_winner = candidate, nonfusion_votes = major_party_votes)# Compare outcomeselection_outcomes <- winners_fusion %>%inner_join(winners_nonfusion, by =c("year", "district")) %>%filter(fusion_winner != nonfusion_winner)# Create the gt table with updated styleselection_outcomes_table <- election_outcomes %>%gt() %>%tab_header(title ="Elections Affected by Fusion Voting System",subtitle ="Comparison of Winners with and without Fusion Voting" ) %>%cols_label(year ="Year",district ="District",fusion_winner ="Winner with Fusion Voting",fusion_votes ="Votes (Fusion)",nonfusion_winner ="Winner without Fusion Voting",nonfusion_votes ="Votes (Non-Fusion)" ) %>%fmt_number(columns =c(fusion_votes, nonfusion_votes),decimals =0 ) %>%tab_options(table.font.size =px(14),heading.align ="center" )# Display the table in Quarto environmentelection_outcomes_table
Elections Affected by Fusion Voting System
Comparison of Winners with and without Fusion Voting
Winner with Fusion Voting
Votes (Fusion)
Winner without Fusion Voting
Votes (Non-Fusion)
1976 - 29
EDWARD W PATTISON
100,663
JOSEPH A MARTINO
96,476
1980 - 3
GREGORY W CARMAN
87,952
JEROME A AMBRO JR
75,389
1980 - 6
JOHN LEBOUTILLIER
89,762
LESTER L WOLFF
74,319
1984 - 20
JOSEPH J DIOGUARDI
106,958
OREN J TEICHER
102,842
1986 - 27
GEORGE C WORTLEY
83,430
ROSEMARY S POOLER
81,133
1992 - 3
PETER T KING
124,727
STEVE A ORLINS
116,915
1994 - 1
MICHAEL P FORBES
90,491
GEORGE J HOCHBRUECKNER
78,692
1996 - 1
MICHAEL P FORBES
116,620
NORA L BREDES
93,816
1996 - 30
JACK QUINN
121,369
FRANCIS J PORDUM
97,686
2006 - 25
JAMES T WALSH
110,525
DAN MAFFEI
100,605
2006 - 29
JOHN R "RANDY" KUHL JR
106,077
ERIC J MASSA
94,609
2010 - 13
MICHAEL G GRIMM
65,024
MICHAEL E MCMAHON
60,773
2010 - 19
NAN HAYMORTH
109,956
JOHN J HALL
98,766
2010 - 24
RICHARD L HANNA
101,599
MICHAEL A ARCURI
89,809
2010 - 25
ANN MARIE BUERKLE
104,602
DANIEL B MAFFEI
103,954
2012 - 27
CHRIS COLLINS
161,220
KATHLEEN C HOCHUL
140,008
2018 - 1
LEE M ZELDIN
139,027
PERRY GERSHON
124,213
2018 - 24
JOHN M KATKO
136,920
DANA BALTER
115,902
2018 - 27
CHRIS COLLINS
140,146
NATHAN D MCMURRAY
128,167
2022 - 4
ANTHONY P D’ESPOSITO
140,622
LAURA A GILLEN
130,871
2022 - 17
MICHAEL V LAWLER
143,550
SEAN PATRICK MALONEY
133,457
2022 - 22
BRANDON M WILLIAMS
135,544
FRANCIS CONOLE
132,913
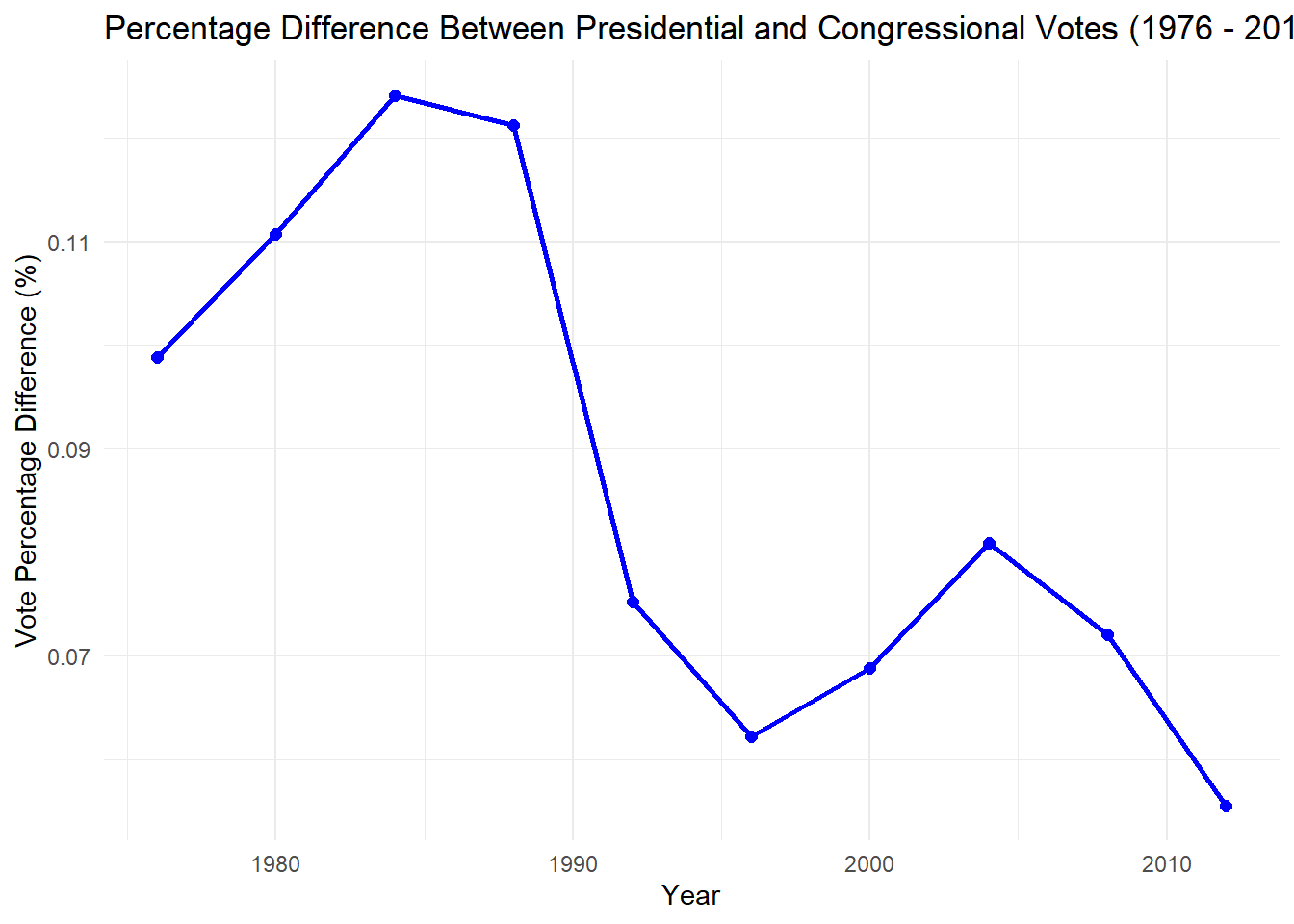
In exploring U.S. voting trends from 1976 to 2012, the code examines whether presidential candidates typically receive more votes than their party’s congressional candidates within the same state. It filters and aggregates vote data for both presidential and congressional races by year, then calculates the percentage difference between the total votes for presidential and congressional candidates. The results are presented in a formatted table using the gt package, and a line plot visualizes the vote percentage difference over time. The analysis reveals a general trend of decreasing presidential vote share relative to congressional vote share over the years, highlighting variations in the relationship between presidential and congressional vote shares across different election years and states.
Show the code
#3.3# Filter and aggregate presidential votespresidential_votes <- president_data %>%filter(office =="US PRESIDENT", year >=1976, year <=2012) %>%group_by(year) %>%summarise(total_president_votes =sum(candidatevotes), .groups ="drop")# Filter and aggregate congressional votescongressional_votes <- house_data %>%filter(office =="US HOUSE", year >=1976, year <=2012) %>%group_by(year) %>%summarise(total_congress_votes =sum(candidatevotes), .groups ="drop")# Combine the datasetsvote_comparison <- presidential_votes %>%left_join(congressional_votes, by ="year")# Calculate vote percentage differencevote_comparison <- vote_comparison %>%mutate(vote_percentage_difference = (total_president_votes - total_congress_votes) / total_congress_votes)# Create a gt tablevote_table <- vote_comparison %>%gt() %>%tab_header(title ="Total Votes for Presidential and Congressional Candidates (1976 - 2012)" ) %>%cols_label(year ="Year",total_president_votes ="Total Presidential Votes",total_congress_votes ="Total Congressional Votes",vote_percentage_difference ="Vote Percentage Difference (%)" ) %>%fmt_number(columns =c(total_president_votes, total_congress_votes), decimals =0 ) %>%fmt_percent(columns = vote_percentage_difference,decimals =1 )# Plotting the vote percentage difference over the yearsggplot(vote_comparison, aes(x = year, y = vote_percentage_difference)) +geom_line(color ="blue", size =1) +geom_point(color ="blue", size =2) +labs(title ="Percentage Difference Between Presidential and Congressional Votes (1976 - 2012)",x ="Year",y ="Vote Percentage Difference (%)") +theme_minimal()
Show the code
# Display the gt tablevote_table
Total Votes for Presidential and Congressional Candidates (1976 - 2012)
Year
Total Presidential Votes
Total Congressional Votes
Vote Percentage Difference (%)
1976
81,601,344
74,259,171
9.9%
1980
86,496,851
77,873,913
11.1%
1984
92,654,861
82,421,874
12.4%
1988
91,586,825
81,682,171
12.1%
1992
104,599,780
97,281,410
7.5%
1996
96,389,818
90,745,365
6.2%
2000
105,593,982
98,799,965
6.9%
2004
122,349,450
113,191,293
8.1%
2008
131,419,253
122,586,298
7.2%
2012
129,139,997
122,345,021
5.6%
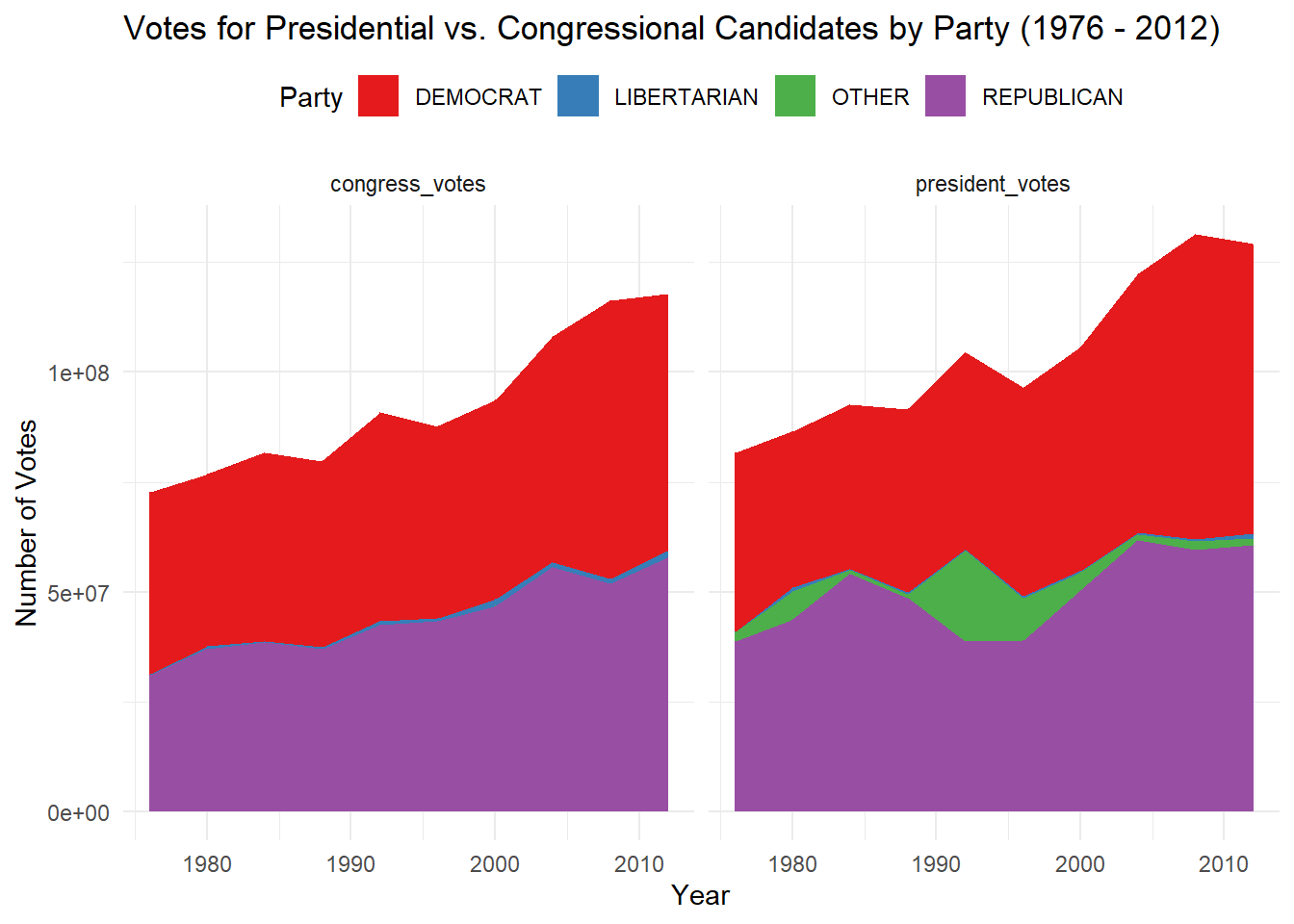
I also analyze voting patterns for presidential and congressional candidates by party from 1976 to 2012. The code aggregates the vote totals by year and party for both presidential and congressional races, then merges the datasets to facilitate comparison. The data is reshaped into a long format for easier visualization, and a stacked area chart is created to display the number of votes for each party in both presidential and congressional elections over time. The chart highlights a consistent trend of presidential candidates receiving more votes than congressional candidates, helping to identify shifts in party performance across years and races.
Show the code
#3.3# Aggregate votes by party for presidential and congressional candidatesparty_votes <- president_data %>%filter(office =="US PRESIDENT", year >=1976, year <=2012) %>%group_by(year, party_simplified) %>%summarise(president_votes =sum(candidatevotes), .groups ="drop") %>%rename(party = party_simplified)congressional_party_votes <- house_data %>%filter(office =="US HOUSE", year >=1976, year <=2012) %>%group_by(year, party) %>%summarise(congress_votes =sum(candidatevotes), .groups ="drop")# Combine the datasetsparty_vote_comparison <- party_votes %>%left_join(congressional_party_votes, by =c("year", "party"))# Reshape data to long formatparty_vote_long <- party_vote_comparison %>%pivot_longer(cols =c(president_votes, congress_votes), names_to ="vote_type", values_to ="votes")# Plotting stacked area graph by partyggplot(party_vote_long, aes(x = year, y = votes, fill = party)) +geom_area(position ="stack") +facet_wrap(~ vote_type) +labs(title ="Votes for Presidential vs. Congressional Candidates by Party (1976 - 2012)",x ="Year",y ="Number of Votes",fill ="Party") +theme_minimal() +scale_fill_brewer(palette ="Set1") +theme(legend.position ="top")
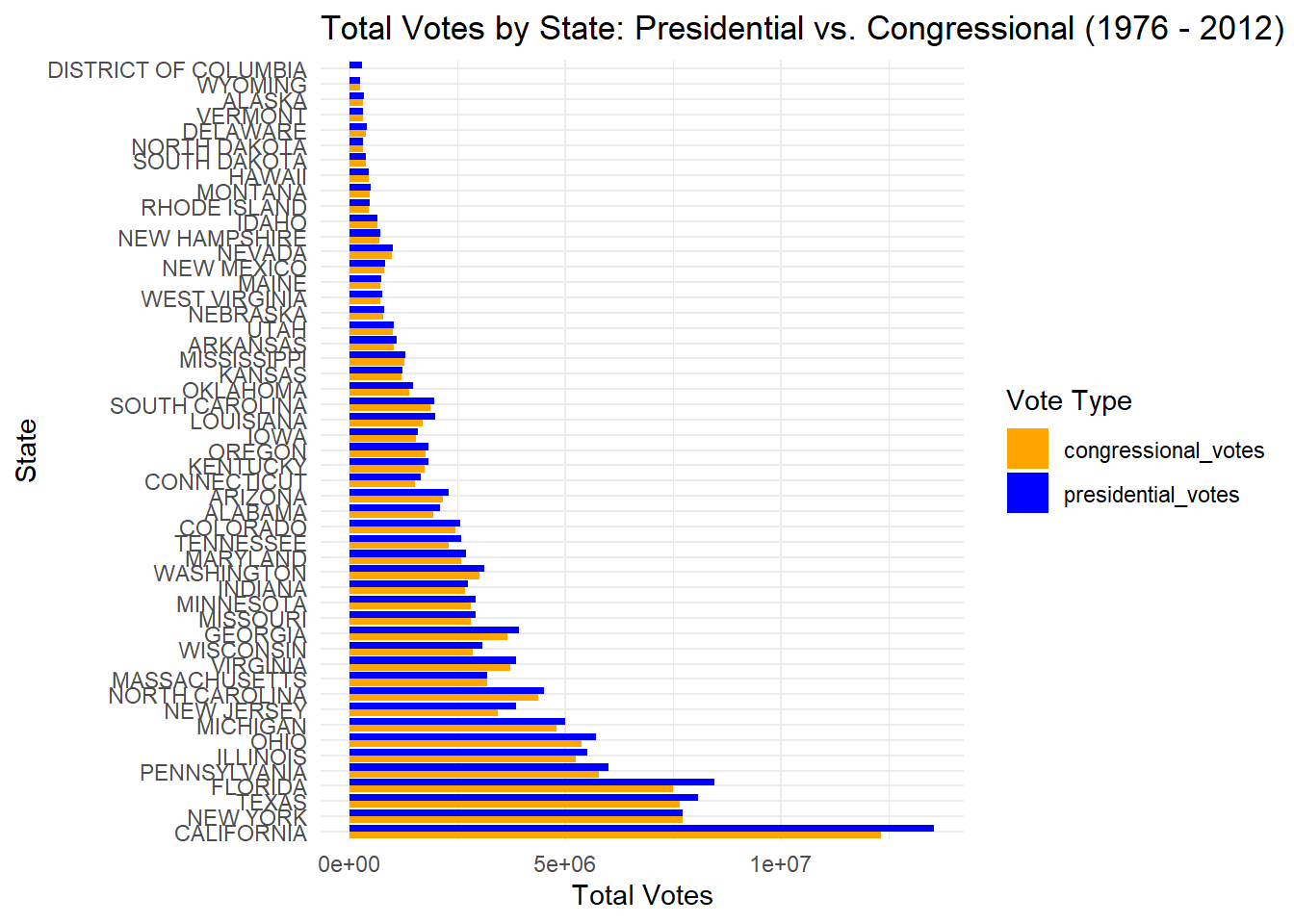
Additionally, I analyze the total votes by state in presidential and congressional elections from 1976 to 2012. The code aggregates vote totals by year and state for both races, then merges the datasets for comparison. The data is reshaped into a long format for better visualization, and a grouped bar chart is created to display the total votes for presidential and congressional candidates by state. The chart highlights that states with larger populations, such as California and New York, have higher vote totals, with presidential candidates consistently receiving more votes than congressional candidates in these states.
Show the code
#3.3# Aggregate votes by state for presidential and congressional candidatesstate_vote_comparison <- president_data %>%filter(office =="US PRESIDENT", year >=1976, year <=2012) %>%group_by(state, year) %>%summarise(presidential_votes =sum(candidatevotes), .groups ="drop")congressional_state_votes <- house_data %>%filter(office =="US HOUSE", year >=1976, year <=2012) %>%group_by(state, year) %>%summarise(congressional_votes =sum(candidatevotes), .groups ="drop")# Combine the datasetsstate_votes_combined <- state_vote_comparison %>%left_join(congressional_state_votes, by =c("state", "year"))# Reshape data to long format for ggplotstate_votes_long <- state_votes_combined %>%pivot_longer(cols =c(presidential_votes, congressional_votes), names_to ="vote_type", values_to ="votes")# Plotting grouped bar chart for votes by stateggplot(state_votes_long, aes(x =reorder(state, -votes), y = votes, fill = vote_type)) +geom_bar(stat ="identity", position ="dodge") +labs(title ="Total Votes by State: Presidential vs. Congressional (1976 - 2012)",x ="State",y ="Total Votes",fill ="Vote Type") +theme_minimal() +coord_flip() +# Flip coordinates for better visibilityscale_fill_manual(values =c("presidential_votes"="blue", "congressional_votes"="orange"))
Importing and Plotting Shape File Data
Next, I extract and read shapefiles from zip archives using R’s sf library, which is designed for handling spatial data in visualization and analysis. The code defines two functions: read_ucla_shapefiles and read_census_shapefiles. The first function extracts and reads all .shp files from zip archives in a specified directory, while the second function focuses on specific Census shapefiles based on a list of filenames. Both functions utilize sf::st_read to load the shapefiles and handle any errors, returning a list of successfully read shapefiles for further analysis.
# Function to read UCLA shapefiles into Rread_ucla_shapefiles <-function(directory) { shapefiles <-list.files(directory, pattern ="\\.zip$", full.names =TRUE) results <-list()for (zip_file in shapefiles) { unzip_dir <-tempdir()unzip(zip_file, exdir = unzip_dir) shp_files <-list.files(unzip_dir, pattern ="\\.shp$", full.names =TRUE, recursive =TRUE)for (shp_file in shp_files) {tryCatch({ sf_object <- sf::st_read(shp_file, quiet=TRUE) results[[basename(shp_file)]] <- sf_object }, error =function(e) {message(paste("Error reading file:", shp_file, ":", e$message)) }) } }return(results)}# Define the shapefile directoryucla_dir <-"data/shapefiles"# Read the downloaded UCLA shapefiles into Rucla_shapefiles <-read_ucla_shapefiles(ucla_dir)
Reading data II
Show the code
# Function to read specific Census shapefiles into R# Function to read specific Census shapefiles into Rread_census_shapefiles <-function(directory, filenames) { shapefiles <-list.files(directory, pattern ="\\.zip$", full.names =TRUE) results <-list()for (zip_file in shapefiles) { unzip_dir <-tempdir()unzip(zip_file, exdir = unzip_dir) shp_files <-list.files(unzip_dir, pattern ="\\.shp$", full.names =TRUE, recursive =TRUE)for (shp_file in shp_files) {# Check if the shapefile matches the desired filenamesif (basename(shp_file) %in% filenames) {tryCatch({ sf_object <- sf::st_read(shp_file, quiet =TRUE) results[[basename(shp_file)]] <- sf_object }, error =function(e) {message(paste("Error reading file:", shp_file, ":", e$message)) }) } } }return(results)}# List of specific filenames to readdesired_filenames <-c("tl_2014_us_cd114.shp","tl_2015_us_cd114.shp","tl_2016_us_cd115.shp","tl_2017_us_cd115.shp","tl_2018_us_cd116.shp","tl_2019_us_cd116.shp","tl_2020_us_cd116.shp","tl_2021_us_cd116.shp","tl_2022_us_cd116.shp")# Define the Census shapefile directorycensus_dir <-"data/census_shapefiles"# Read the downloaded Census shapefiles into Rcensus_shapefiles <-read_census_shapefiles(census_dir, desired_filenames)
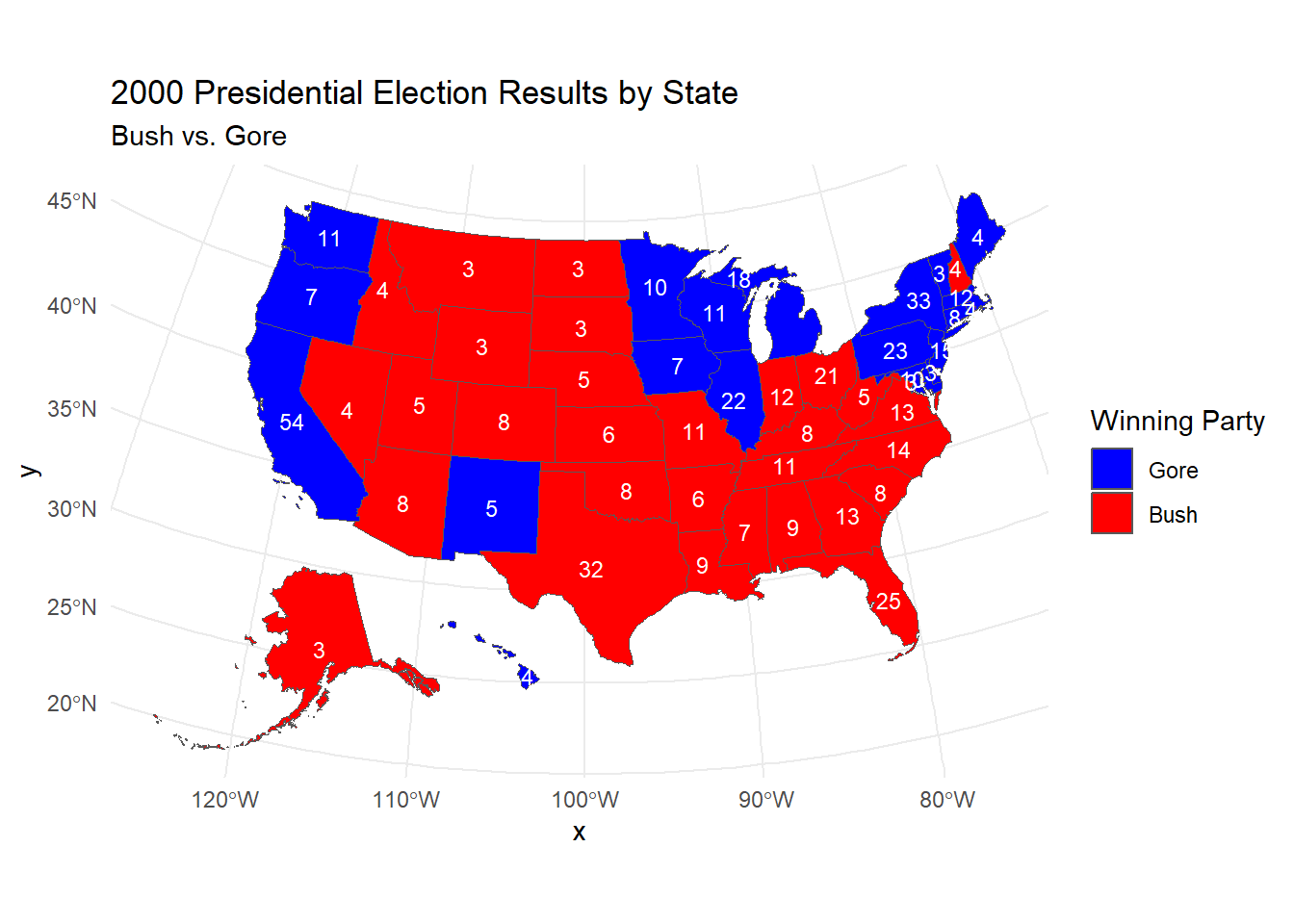
Using the data previously downloaded, here is the choropleth visualization of the 2000 U.S. Presidential Election Electoral College results.
Show the code
#Task5# Step 1: Prepare Congressional District DataCD_106 <- ucla_shapefiles[["districts106.shp"]] %>%mutate(STATENAME =tolower(STATENAME)) %>%select(-geometry) %>%as.data.frame() %>%group_by(STATENAME) %>%summarize(EC =n() +2) # Electoral votes per state (Districts + 2 for Senate)# Step 2: Get vote results for the year 2000vote_results_2000 <- president_data %>%filter(year ==2000) %>%mutate(state =tolower(state)) %>%group_by(state) %>%summarize(winning_party = party_simplified[which.max(candidatevotes)],total_votes =max(totalvotes) ) %>%ungroup()# Step 3: Special case adjustments for Minnesota & Vermontvote_results_2000 <- vote_results_2000 %>%mutate(winning_party =ifelse(state =="minnesota"& winning_party =="DEMOCRATIC-FARMER-LABOR", "DEMOCRAT", winning_party),winning_party =ifelse(state =="vermont", "DEMOCRAT", winning_party) )# Step 4: Combine EC with winning party dataEC_2000 <- CD_106 %>%left_join(vote_results_2000, by =c("STATENAME"="state")) %>%mutate(winning_party =if_else(STATENAME =="district of columbia"&is.na(winning_party), "DEMOCRAT", winning_party) ) %>%select(STATENAME, winning_party, EC)# Step 5: Rename columns to match `usmap` requirementsEC_2000 <- EC_2000 %>%rename(state = STATENAME)# Step 6: Add state abbreviations to the EC_2000 datastate_abbreviations <-data.frame(state =tolower(c("alabama", "alaska", "arizona", "arkansas", "california", "colorado", "connecticut", "delaware", "florida", "georgia", "hawaii", "idaho", "illinois", "indiana", "iowa", "kansas", "kentucky", "louisiana", "maine", "maryland", "massachusetts", "michigan", "minnesota", "mississippi", "missouri", "montana", "nebraska", "nevada", "new hampshire", "new jersey", "new mexico", "new york", "north carolina", "north dakota", "ohio", "oklahoma", "oregon", "pennsylvania", "rhode island", "south carolina", "south dakota", "tennessee", "texas", "utah", "vermont", "virginia", "washington", "west virginia", "wisconsin", "wyoming", "district of columbia")),abbreviation =c("AL", "AK", "AZ", "AR", "CA", "CO", "CT", "DE", "FL", "GA", "HI", "ID", "IL", "IN", "IA", "KS", "KY", "LA", "ME", "MD", "MA", "MI", "MN", "MS", "MO", "MT", "NE", "NV", "NH", "NJ", "NM", "NY", "NC", "ND", "OH", "OK", "OR", "PA", "RI", "SC", "SD", "TN", "TX", "UT", "VT", "VA", "WA", "WV", "WI", "WY", "DC"))# Step 7: Merge state abbreviations with EC_2000 dataEC_2000 <-left_join(EC_2000, state_abbreviations, by ="state") %>%rename(Abbreviation = abbreviation) # Rename 'abbreviation' to 'Abbreviation'# Step 8: Get the US map data (this provides state geometries)us_states <- usmap::us_map(regions ="states") # Correct way to get state geometries# Step 9: Rename 'abbreviation' to 'abbr' in EC_2000 to match the column name in us_statesEC_2000 <- EC_2000 %>%rename(abbr = Abbreviation)# Ensure map_data_cleaned is a data frame before joiningmap_data_with_geom <- EC_2000 %>%left_join(us_states, by =c("abbr"="abbr")) %>%select(everything(), geom)# Rename 'geom' to 'geometry' for consistencymap_data_with_geom <- map_data_with_geom %>%rename(geometry = geom)# Convert to Simple Features (sf) object for plottingmap_data_with_geom_sf <-st_as_sf(map_data_with_geom)# Plot using ggplot2ggplot(map_data_with_geom_sf) +geom_sf(aes(fill = winning_party)) +# Color states by winning partyscale_fill_manual(values =c("DEMOCRAT"="blue", "REPUBLICAN"="red"),labels =c("DEMOCRAT"="Gore", "REPUBLICAN"="Bush"),name ="Winning Party") +geom_sf_text(aes(label = EC), size =3, color ="white") +# Add electoral vote labels to stateslabs(title ="2000 Presidential Election Results by State",subtitle ="Bush vs. Gore") +theme_minimal() # Use minimal theme
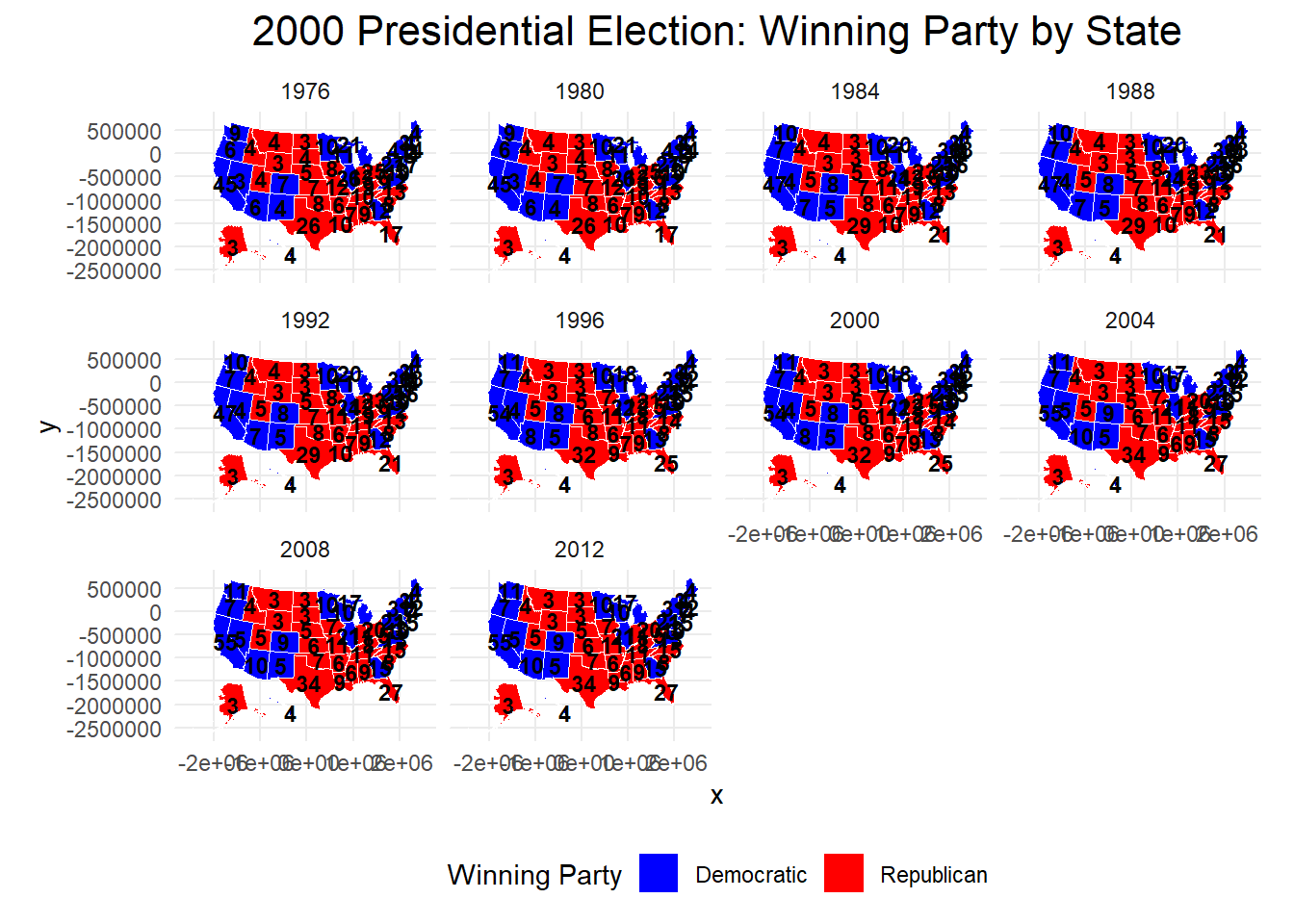
The faceted version showing election results over time is as follows:
Show the code
#Task6library(usmap)library(tools)library(sf)library(tigris)library(dplyr)library(ggplot2)library(gganimate)# Modify the function to return data for all yearsgenerate_choropleth_data_for_year <-function(year, district_number, president_data, ucla_shapefiles) {# Load the specific district shapefile district_shapefile <- ucla_shapefiles[[paste0("districts", district_number, ".shp")]]# Create Electoral College votes column based on the district shapefile district_EC <- district_shapefile %>%mutate(STATENAME =toupper(STATENAME)) %>%select(-geometry) %>%as.data.frame() %>%group_by(STATENAME) %>%summarize(EC =n() +2) # 2 for senators per state# Filter the election data for the given year president_year <- president_data %>%filter(year == year) %>%group_by(state) %>%mutate(winning_party = party_simplified[which.max(candidatevotes)] # Determine the winning party ) %>%slice_max(candidatevotes, n =1) %>%# Only keep the row with the highest total votesungroup() # Ungroup after summarizing# Join the election data with the district data (EC votes and winning party) president_EC <- district_EC %>%left_join(president_year, by =c("STATENAME"="state")) %>%select(state = STATENAME, EC, winning_party, state_fips)# Load U.S. state shapefiles for mapping us_state_shapefiles <- usmap::us_map(regions ="states") %>%mutate(fips =as.integer(fips))# Merge district data with state shapefiles by FIPS code merged_data <- president_EC %>%left_join(us_state_shapefiles, by =c("state_fips"="fips"))# Add the year column to merge data merged_data$year <- year# Return the merged data for all years (instead of a plot)return(merged_data)}# Generate data for all election yearsall_years_data <-bind_rows(generate_choropleth_data_for_year(1976, "094", president_data, ucla_shapefiles),generate_choropleth_data_for_year(1980, "096", president_data, ucla_shapefiles),generate_choropleth_data_for_year(1984, "098", president_data, ucla_shapefiles),generate_choropleth_data_for_year(1988, "100", president_data, ucla_shapefiles),generate_choropleth_data_for_year(1992, "102", president_data, ucla_shapefiles),generate_choropleth_data_for_year(1996, "104", president_data, ucla_shapefiles),generate_choropleth_data_for_year(2000, "106", president_data, ucla_shapefiles),generate_choropleth_data_for_year(2004, "108", president_data, ucla_shapefiles),generate_choropleth_data_for_year(2008, "110", president_data, ucla_shapefiles),generate_choropleth_data_for_year(2012, "112", president_data, ucla_shapefiles))# facet graph, work on getting in one columnggplot(data = all_years_data) +geom_sf(aes(fill = winning_party, geometry = geom), color ="white", size =2.0) +# Color by winning partyscale_fill_manual(values =c("REPUBLICAN"="red", "DEMOCRAT"="blue"), labels =c("REPUBLICAN"="Republican", "DEMOCRAT"="Democratic"), name ="Winning Party") +# Red for Republican, Blue for Democratgeom_sf_text(aes(label = EC, geometry = geom), color ="black", size =3, fontface ="bold") +# Add EC vote labelstheme_minimal() +labs(title ="2000 Presidential Election: Winning Party by State") +# Removed subtitletheme(legend.position ="bottom", plot.title =element_text(hjust =0.5, size =16)) +facet_wrap(~ year)
Comparing the Effects of ECV Allocation Rules
The following code includes different historical voting data and assigns each state’s Electoral College votes (ECVs) according to various strategies:
Task 7 - State-Wide Winner-Take-All
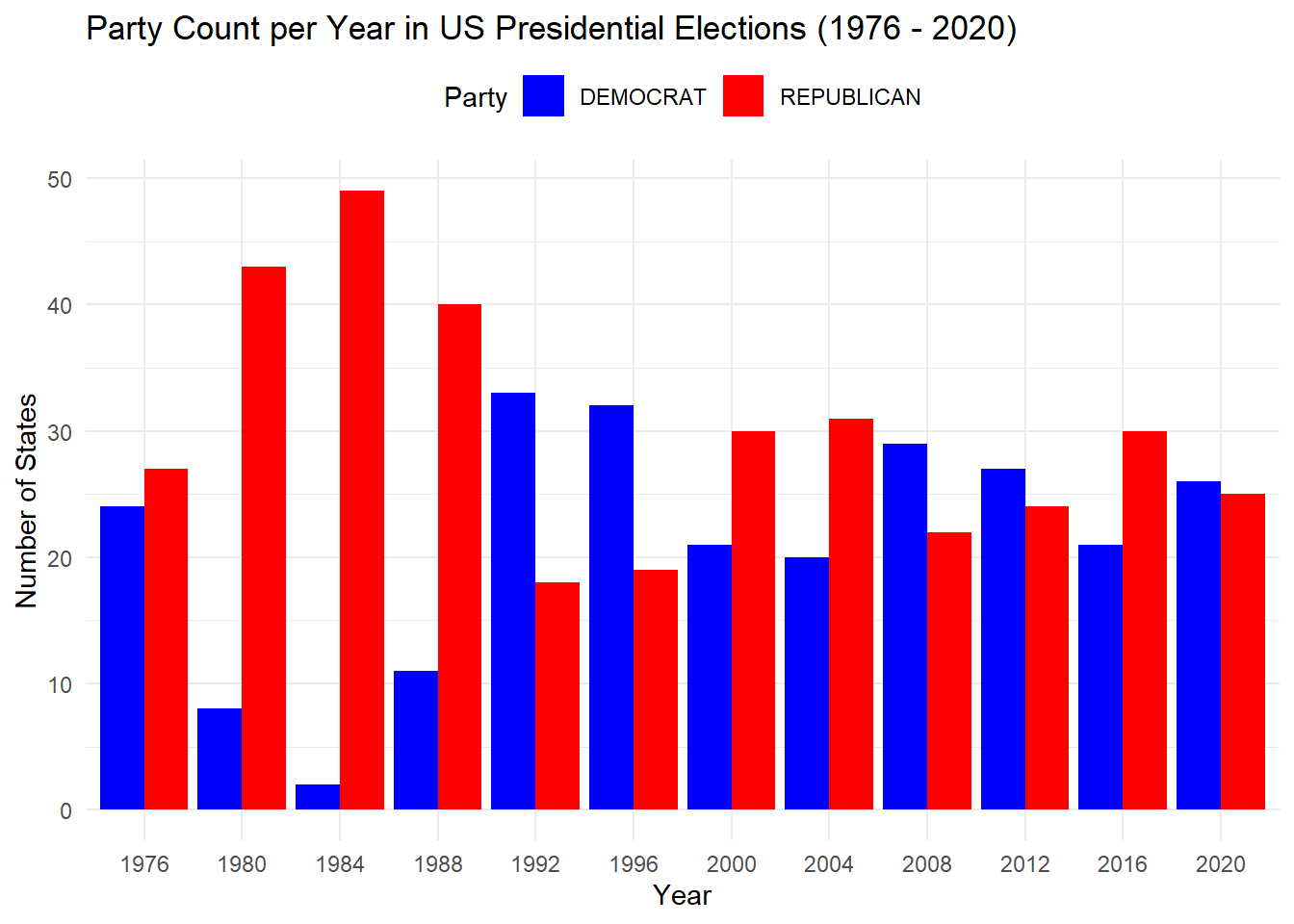
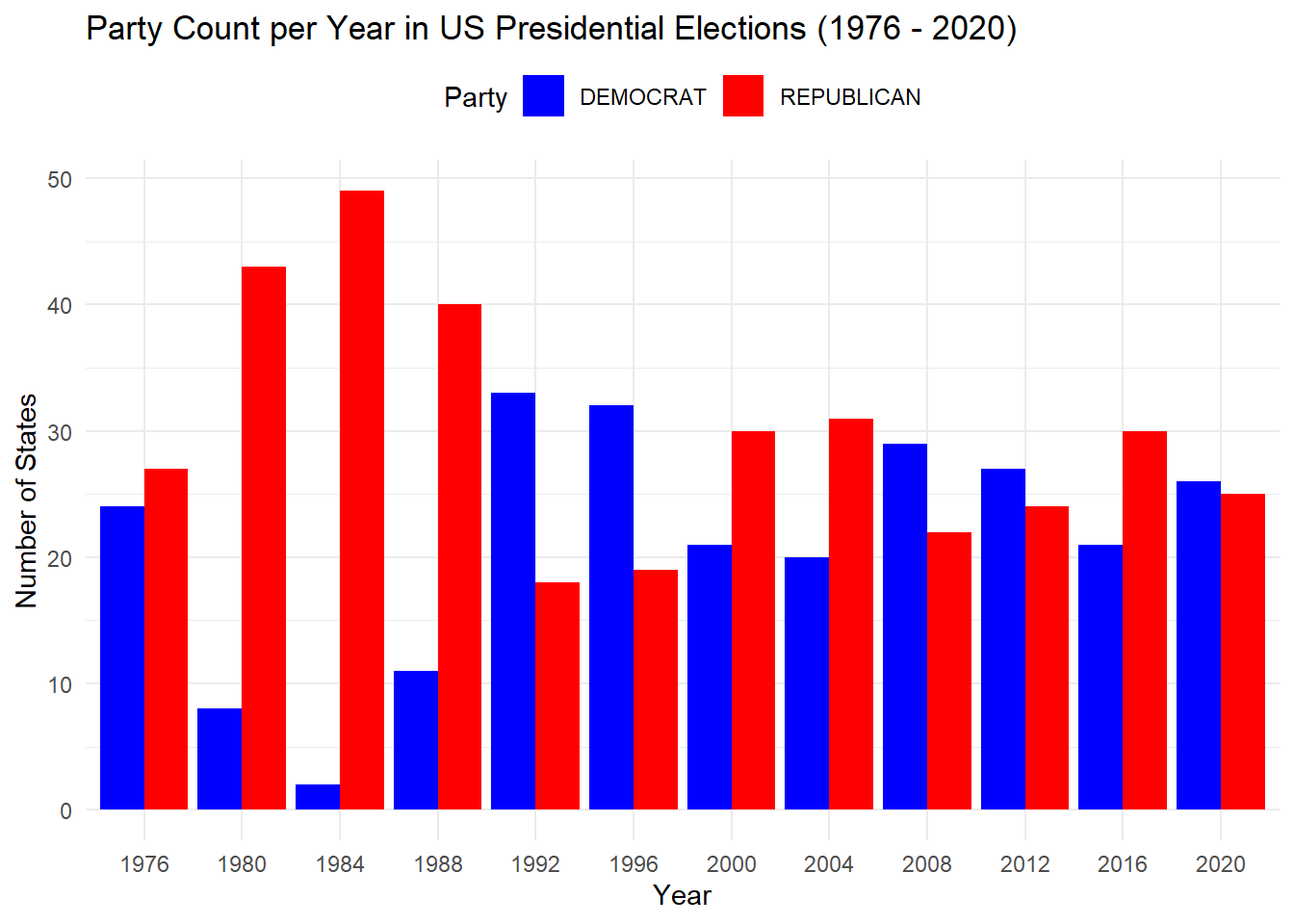
This strategy and code focuses on filtering U.S. presidential election data between 1976 and 2020, identifying the candidate with the highest vote in each state for each election year. This is done using the dplyr package to group and filter the data based on the maximum vote count per state, followed by summarizing to capture the winner, their party, and the highest votes. The results are displayed in a formatted table using the gt package and a bar chart is created to show the count of each party winning by state across the years.
Show the code
#| code-fold: true#| code-summary: "Show the code"library(dplyr)library(DT)library(ggplot2)# Sample 1000 rows or fewer from each table for displaydisplay_sample <-function(data, table_name) { sample_data <- data[sample(nrow(data), min(1000, nrow(data))), ] # Sample 1000 rows or fewerdatatable( sample_data,options =list(pageLength =10, # Display 10 rows per pagescrollX =TRUE, # Enable horizontal scrollingdom ='tip'# Only show table, input filter, and pagination ),caption =paste("Sample of", table_name, "(Up to 1000 rows)") )}# Filter data for all presidential election years from 1976 to 2020state_winner <- president_data %>%filter(office =="US PRESIDENT", year %in%seq(1976, 2020, by =4)) %>%# Include all presidential election yearsgroup_by(year, state) %>%filter(candidatevotes ==max(candidatevotes, na.rm =TRUE)) %>%summarise(winner =first(candidate),party =first(party_simplified),highest_votes =max(candidatevotes, na.rm =TRUE),.groups ="drop" )# Display a sample of the state_winner tabledisplay_sample(state_winner, "State Winners")
Show the code
# Calculate party counts per year for the bar chartparty_count_per_year <- state_winner %>%count(year, party) %>%arrange(year, desc(n)) # Arrange the data for better display in the bar chart# Create a bar chart to show the count of each party per yearggplot(party_count_per_year, aes(x =factor(year), y = n, fill = party)) +geom_bar(stat ="identity", position ="dodge") +labs(title ="Party Count per Year in US Presidential Elections (1976 - 2020)",x ="Year",y ="Number of States",fill ="Party" ) +scale_fill_manual(values =c("DEMOCRAT"="blue", "REPUBLICAN"="red", "OTHER"="grey")) +theme_minimal() +theme(legend.position ="top")
This code starts similarly by filtering data from the same period, but it focuses on calculating the total candidate votes for each party in each state, rather than identifying a single candidate’s vote. The party with the highest total votes is considered the winner for that state in each election year. The results are again shown in a gt table and visualized with a bar chart that counts the number of states won by each party for every election year, providing insights into the distribution of electoral outcomes across the U.S.
Show the code
# Load necessary librarieslibrary(dplyr)library(DT)library(ggplot2)# Filter for presidential data in all election years from 1976 to 2020filtered_data <- president_data %>%filter(office =="US PRESIDENT", year %in%seq(1976, 2020, by =4))# Step 1: Determine the highest candidate votes for each party by state and yearhighest_votes_per_party <- filtered_data %>%group_by(year, state, party_simplified) %>%summarise(total_votes =sum(candidatevotes, na.rm =TRUE), .groups ="drop")# Step 2: Identify the winning party for each state and year based on the highest votesstate_winners_atlarge <- highest_votes_per_party %>%group_by(year, state) %>%filter(total_votes ==max(total_votes)) %>%slice(1) %>%# Select first in case of tiesungroup()# Display the winning party data sample using display_sample functiondisplay_sample(state_winners_atlarge, "Winning Party by State in US Presidential Elections (1976 - 2020)")
Show the code
# Step 3: Bar chart for party count per yearparty_count_per_year <- state_winners_atlarge %>%count(year, party_simplified) %>%arrange(year, desc(n)) # Arrange the data for better display in the bar chart# Create a bar chart to show the count of each party per yearggplot(party_count_per_year, aes(x =factor(year), y = n, fill = party_simplified)) +geom_bar(stat ="identity", position ="dodge") +labs(title ="Party Count per Year in US Presidential Elections (1976 - 2020)",x ="Year",y ="Number of States",fill ="Party" ) +scale_fill_manual(values =c("DEMOCRAT"="blue", "REPUBLICAN"="red", "OTHER"="grey")) +theme_minimal() +theme(legend.position ="top")
Show the code
#EC Tableslibrary(dplyr)library(stringr)# Define a function to generate EC data for a specific election yeargenerate_ec_table <-function(year, district_file, president_data, ucla_shapefiles, state_abbreviations) {# Load the shapefile for the corresponding congressional districts congressional_districts <- ucla_shapefiles[[paste0("districts", district_file, ".shp")]] %>%mutate(STATENAME =tolower(STATENAME)) %>%select(-geometry) %>%as.data.frame() %>%group_by(STATENAME) %>%summarize(EC =n() +2) # EC based on the number of districts + 2 senators per state# Filter and summarize presidential data for the given year vote_results <- president_data %>%filter(year == year) %>%mutate(state =tolower(state)) %>%group_by(state) %>%summarize(winning_party = party_simplified[which.max(candidatevotes)],total_votes =max(totalvotes) ) %>%ungroup()# Combine EC with winning party information ec_table <- congressional_districts %>%left_join(vote_results, by =c("STATENAME"="state")) %>%mutate(winning_party =if_else(STATENAME =="district of columbia"&is.na(winning_party), "DEMOCRAT", winning_party) ) %>%select(STATENAME, winning_party, EC)# Rename columns to match `usmap` requirements and merge state abbreviations ec_table <- ec_table %>%rename(state = STATENAME) %>%left_join(state_abbreviations, by ="state") %>%rename(Abbreviation = abbreviation) # Rename 'abbreviation' to 'Abbreviation'return(ec_table)}# List of years and corresponding district shapefile codesyears_and_districts <-list(c(1976, "094"), c(1980, "096"), c(1984, "098"), c(1988, "100"), c(1992, "102"), c(1996, "104"), c(2000, "106"), c(2004, "108"), c(2008, "110"), c(2012, "112"))# Loop through each year and generate the EC tablesec_tables <-lapply(years_and_districts, function(info) { year <- info[1] district_file <- info[2]generate_ec_table(as.numeric(year), district_file, president_data, ucla_shapefiles, state_abbreviations)})# Assign each generated EC table to a named list element for easy referencenames(ec_tables) <-paste0("EC_", sapply(years_and_districts, `[[`, 1))
Task 7 - State-Wide Proportional
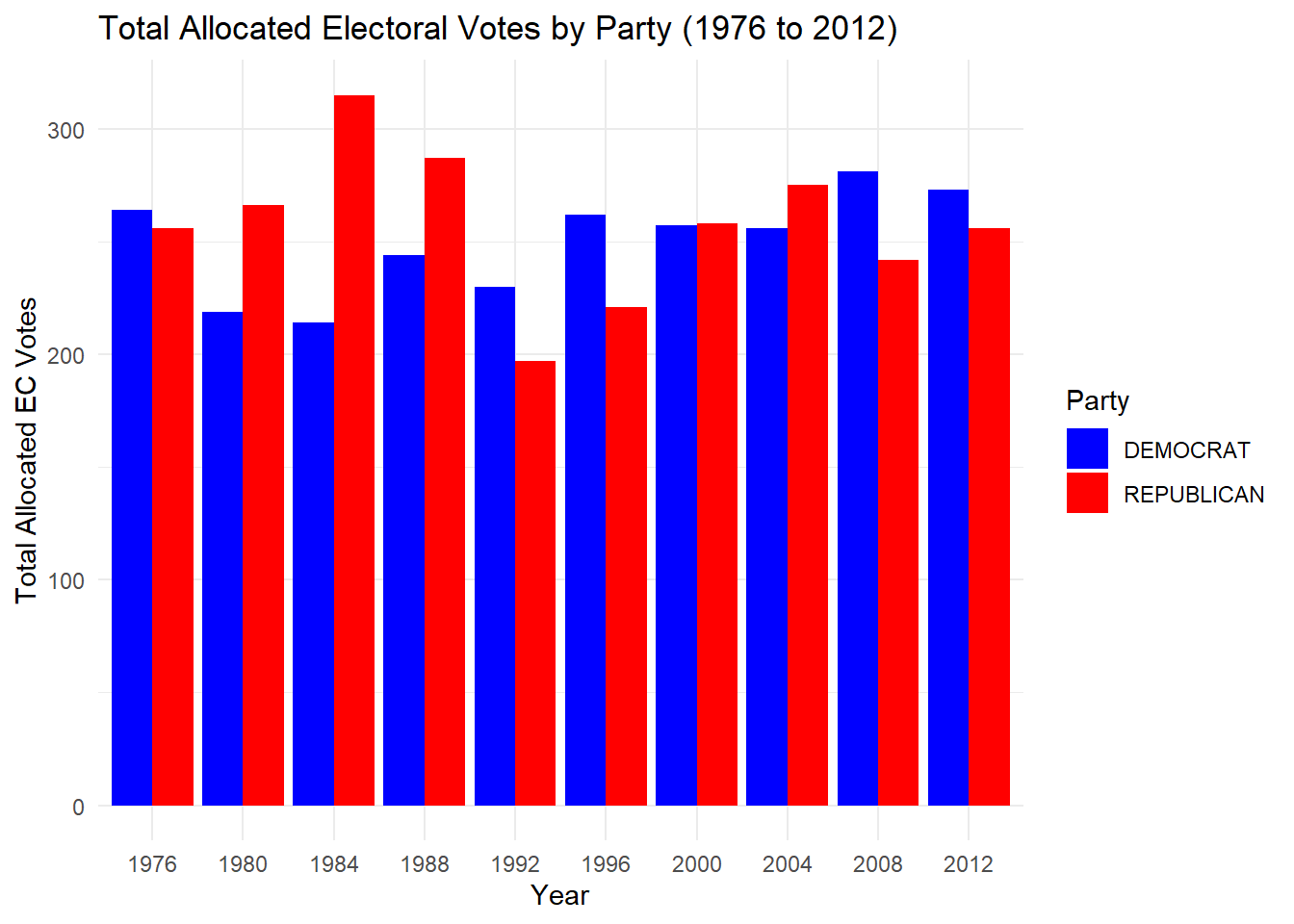
Next, this strategy and code focuses on filtering U.S. presidential election data between 1976 and 2020, identifying the candidate with the highest vote in each state for each election year. This is done using the dplyr package to group and filter the data based on the maximum vote count per state, followed by summarizing to capture the winner, their party, and the highest votes. The results are displayed in a formatted table using the gt package and a bar chart is created to show the count of each party winning by state across the years.
Show the code
library(dplyr)library(ggplot2)# Step 1: Combine all electoral college data into a single dataframe from 1976 to 2012ec_data <-bind_rows(lapply(names(ec_tables), function(name) { year <-as.numeric(sub("EC_", "", name))mutate(ec_tables[[name]], year = year) }))# Step 2: Filter for presidential data in all required years (1976 to 2012)filtered_data <- president_data %>%filter(office =="US PRESIDENT", year %in%seq(1976, 2012, 4)) # Only presidential election years# Step 3: Find the winning candidate for Democrat and Republican parties in each state and yearparty_winners <- filtered_data %>%filter(party_simplified %in%c("DEMOCRAT", "REPUBLICAN")) %>%group_by(year, state, party_simplified) %>%summarise(candidate = candidate[which.max(candidatevotes)], # Get candidate with highest votes per partycandidate_votes =max(candidatevotes, na.rm =TRUE),total_state_votes =max(totalvotes, na.rm =TRUE),.groups ="drop" ) %>%mutate(vote_percentage = candidate_votes / total_state_votes) # Calculate percentage of votes# Ensure consistent formatting of state namesparty_winners <- party_winners %>%mutate(state =str_to_title(state))ec_data <- ec_data %>%mutate(state =str_to_title(state))# Step 4: Join with EC data and calculate allocated EC votesproportional_ec_votes <- party_winners %>%left_join(ec_data, by =c("year", "state")) %>%mutate(allocated_ec_votes =round(EC * vote_percentage) ) %>%select(year, state, candidate, party_simplified, EC, vote_percentage, allocated_ec_votes)# Step 5: Calculate total allocated EC votes by year and partytotal_ec_votes_by_party <- proportional_ec_votes %>%group_by(year, party_simplified) %>%summarise(total_allocated_ec_votes =sum(allocated_ec_votes, na.rm =TRUE), .groups ="drop")# Step 6: Create bar chart for EC votes by year and partyec_votes_bar_chart <-ggplot(total_ec_votes_by_party, aes(x =factor(year), y = total_allocated_ec_votes, fill = party_simplified)) +geom_bar(stat ="identity", position ="dodge") +labs(title ="Total Allocated Electoral Votes by Party (1976 to 2012)",x ="Year",y ="Total Allocated EC Votes",fill ="Party" ) +scale_fill_manual(values =c("DEMOCRAT"="blue", "REPUBLICAN"="red")) +theme_minimal()# Display the bar chartprint(ec_votes_bar_chart)
Task 7 - National Proportional
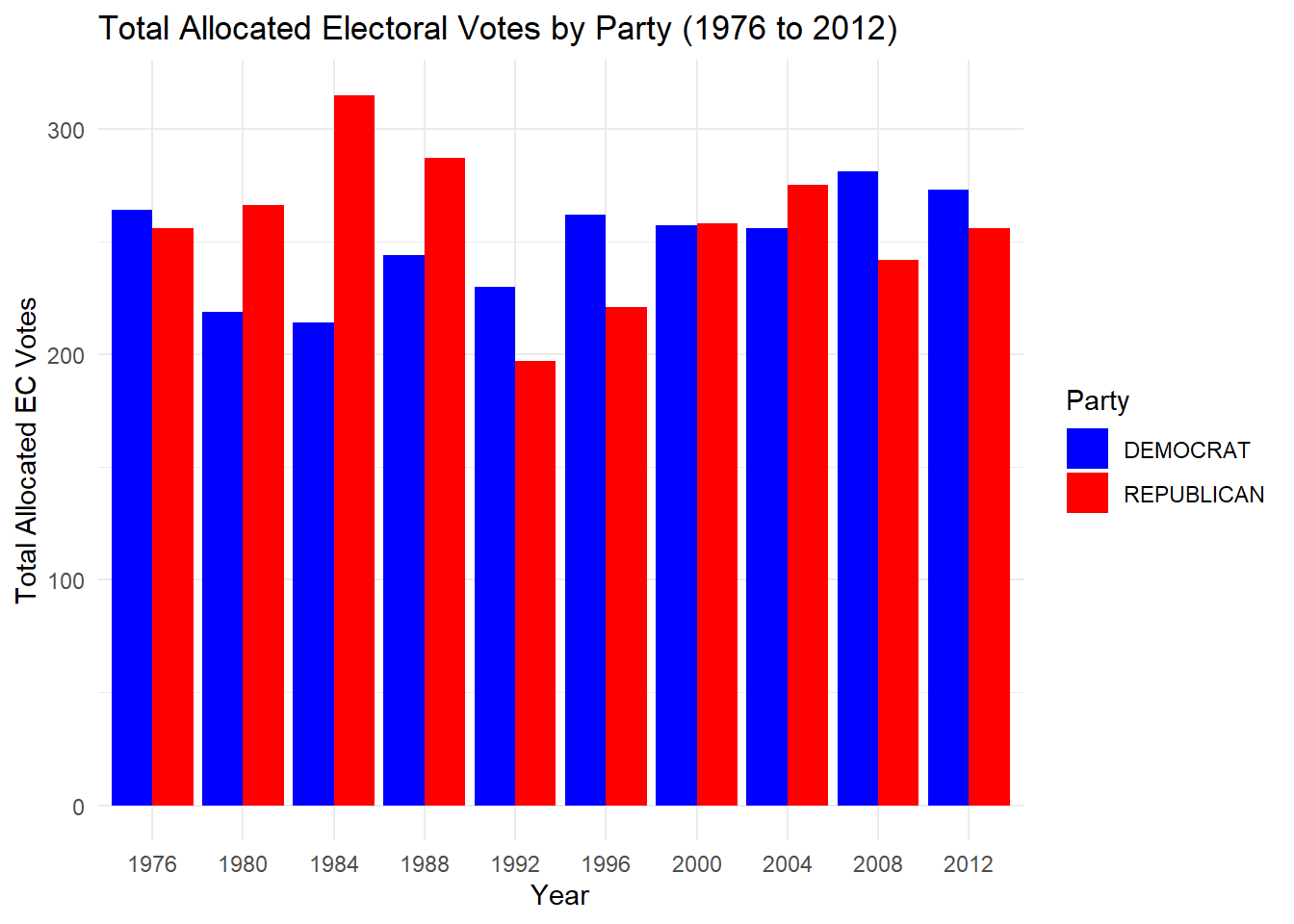
Lastly, the code starts similarly by filtering data from the same period, but it focuses on calculating the total candidate votes for each party in each state, rather than identifying a single candidate’s vote. The party with the highest total votes is considered the winner for that state in each election year. The results are again shown in a gt table and visualized with a bar chart that counts the number of states won by each party for every election year, providing insights into the distribution of electoral outcomes across the U.S.
Show the code
# Step 3: Calculate vote percentage for Democrat and Republican parties in each state and yearparty_percentage <- filtered_data %>%filter(party_simplified %in%c("DEMOCRAT", "REPUBLICAN")) %>%group_by(year, state, party_simplified) %>%summarise(total_party_votes =sum(candidatevotes, na.rm =TRUE),total_state_votes =max(totalvotes, na.rm =TRUE),.groups ="drop" ) %>%mutate(vote_percentage = total_party_votes / total_state_votes)# Ensure consistent formatting of state namesparty_percentage <- party_percentage %>%mutate(state =str_to_title(state))ec_data <- ec_data %>%mutate(state =str_to_title(state))# Step 4: Join with EC data and calculate allocated EC votes for each party by vote percentageproportional_ec_votes <- party_percentage %>%left_join(ec_data, by =c("year", "state")) %>%mutate(allocated_ec_votes =round(EC * vote_percentage) ) %>%select(year, state, party_simplified, EC, vote_percentage, allocated_ec_votes)# Step 5: Calculate total allocated EC votes by year and partytotal_ec_votes_by_party <- proportional_ec_votes %>%group_by(year, party_simplified) %>%summarise(total_allocated_ec_votes =sum(allocated_ec_votes, na.rm =TRUE), .groups ="drop")# Step 6: Create bar chart for EC votes by year and partyec_votes_bar_chart <-ggplot(total_ec_votes_by_party, aes(x =factor(year), y = total_allocated_ec_votes, fill = party_simplified)) +geom_bar(stat ="identity", position ="dodge") +labs(title ="Total Allocated Electoral Votes by Party (1976 to 2012)",x ="Year",y ="Total Allocated EC Votes",fill ="Party" ) +scale_fill_manual(values =c("DEMOCRAT"="blue", "REPUBLICAN"="red")) +theme_minimal()# Display the bar chartprint(ec_votes_bar_chart)
Evaluating Fairness of ECV Allocation Schemes
In evaluating the fairness of different Electoral College Vote (ECV) allocation schemes, I considered several methods: State-Wide Winner-Take-All, District-Wide Winner-Take-All + State-Wide “At Large” Votes, State-Wide Proportional, and National Proportional. After analyzing the results, I determined that the State-Wide Proportional method is the fairest. This is because, when applied across various election years, there is no significant variance in the results, and it seems to provide a more balanced representation of the popular vote relative to the electoral vote.
The District-Wide Winner-Take-All + State-Wide “At Large” Votes method, however, exhibits a notable shift in the 1984 election, showing the largest impact and variance. This method tends to amplify the margin of victory for the candidate with a slight statewide edge. In contrast, under the State-Wide Proportional method, the bar chart for 1984 reveals much less variance, reflecting a more equitable distribution of votes.
From this analysis, it is clear that the State-Wide Proportional allocation scheme provides the most consistent and balanced results across elections, while the District-Wide Winner-Take-All method can lead to more dramatic swings in electoral outcomes.
MIT Election Data and Science Lab, 2017, “U.S. House 1976-2022,” https://doi.org/10.7910/DVN/IGOUN2, Harvard Dataverse, v13, UNF:6: Ky5FkettbvohjTSN/IvldA== [fileUNF].↩︎
MIT Election Data and Science Lab, 2017, “U.S. President 1976-2020,” https://doi.org/10.7910/DVN/42MVDX, Harvard Dataverse, v8, UNF:6:F0opd1IRbeY190yVfzglUw== [fileUNF].↩︎